저번 블로그 포스팅에서 아파치 카프카(Apache kafka)에 대해서 알아보았습니다. 차근차근 중요한 용어에 대해서 알아보니 전체적으로 어떻게 동작하고 어떤 원리를 갖고 있는지 알 수 있었죠. 이번에는 간단하게 코드로 해당 용어들을 정리해 보려고 합니다. 🤓
[Kafka] Apache Kafka에 대해서 알아보기 - 컴도리돌이
아파치 카프카는 마이크로서비스와 같은 현대적인 아키텍처에서 매우 유용하게 활용되는 오픈소스 메시지 스트리밍 플랫폼입니다. 현재 여러 IT 서비스와 플랫폼에서 표준처럼 사용되고 있지
comdolidol-i.tistory.com
Kafka 브로커는 메시지를 저장하고, 프로듀서(Producer)또는 컨슈머(consumer)와 데이터를 교환하는 핵심 구성 요소입니다. Spring Boot에서 Kafka 브로커를 설정하는 부분은 application.yml 또는 application.properties 파일에서 spring.kafka.bootstrap-servers를 설정하는 부분입니다. 예를 들어, application.yml 파일에 다음과 같이 설정할 수 있습니다.
spring:
kafka:
bootstrap-servers: broker1:9092,broker2:9092
이 설정은 애플리케이션이 Kafka 클러스터의 브로커와 연결될 수 있도록 합니다. 브로커 리스트 중 하나에 연결되면, 클러스터 내 다른 브로커의 정보를 자동으로 가져오게 됩니다.

브로커 설정에서 주의할 점은 클러스터 내 모든 브로커 주소를 bootstrap-servers에 나열할 필요는 없다는 것입니다. 하지만 최소 두 개 이상의 브로커를 설정해 두는 것이 좋아요. 예를 들어, broker1이 다운되면 클라이언트가 다른 브로커로 연결을 시도할 수 있도록 하는 거죠. 그러나 너무 많은 브로커를 나열하면 초기 연결 과정에서 시간이 불필요하게 소요될 수 있으니, 적절히 균형을 맞추는 것이 중요합니다.
Kafka 클러스터는 브로커의 집합으로 이루어지며, 클라이언트 요청을 분산 처리하고 데이터를 저장합니다. Spring Boot는 클러스터의 메타데이터를 자동으로 관리하기 때문에, 브로커 주소만 설정하면 클러스터와의 통신이 가능합니다. 클러스터의 안정성을 위해 복제본(replica)을 구성할 수 있는데, 이는 메시지 손실을 방지하고 고가용성을 제공합니다.
Kafka 토픽은 메시지를 저장하는 논리적인 단위입니다. Spring Boot에서 특정 토픽에 메시지를 송신하거나 수신하려면 프로듀서와 컨슈머 설정에서 토픽 이름을 지정해야 합니다. 예를 들어, 프로듀서가 메시지를 송신할 때 다음과 같이 작성할 수 있습니다.
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void sendMessage(String topic, String message) {
kafkaTemplate.send(topic, message);
}
여기서 kafkaTemplate을 사용하여 특정 토픽으로 메시지를 보냅니다. 파티션은 토픽 데이터를 분산 저장하기 위한 단위이며, 메시지 키를 기준으로 파티션이 결정됩니다. 예를 들어, 특정 키를 기반으로 메시지를 특정 파티션에 보내려면 다음과 같이 코드를 작성합니다.
kafkaTemplate.send(new ProducerRecord<>("example-topic", "key", "message"));
물론 프로듀서에서 메시지를 송신할 때 불필요한 키 설정은 피하는 게 좋아요. 만약 메시지 키가 불필요한 경우, Kafka는 자동으로 파티션을 랜덤 하게 할당해 줍니다. 그렇기에 아래처럼 간결하게 작성할 수 있죠.
kafkaTemplate.send("example-topic", "message");
Spring Kafka에서 메시지는 기본적으로 문자열 또는 원시 데이터 타입으로 처리됩니다. 위에는 문자열 메시지를 보내는 기본 코드였지만, 복잡한 데이터를 전송하기엔 부적합합니다. 데이터 구조가 복잡하거나 JSON 형식으로 데이터를 유지해야 한다면, 객체를 직렬화하여 메시지로 보내는 것이 일반적이죠.
Gson을 사용해 메시지를 형식으로 직렬화하면 데이터 구조를 유지하면서 전송할 수 있어요.
public void sendJsonMessage(String topic, MessagePayload payload) {
String jsonMessage = gson.toJson(payload); // 객체를 JSON 문자열로 변환
kafkaTemplate.send(topic, jsonMessage);
}
컨슈머 측에서는 수신된 JSON메시지를 Gson으로 다시 객체로 변환하면 됩니다.
MessagePayload payload = gson.fromJson(message, MessagePayload.class); // JSON 문자열을 객체로 변환
System.out.println("Received Message: " + payload.getContent());메시지는 Kafka에서 송신 및 수신되는 데이터의 단위입니다. 프로듀서는 메시지를 생성하고 토픽에 송신하며, 컨슈머는 토픽에서 메시지를 읽습니다. Spring Boot에서는 컨슈머를 설정하기 위해 @KafkaListener 어노테이션을 사용할 수 있어요.
@KafkaListener(topics = "example-topic", groupId = "example-group")
public void listen(String message) {
System.out.println("Received Message: " + message);
}
여기서 @KafkaListener는 특정 토픽(eample-topic)과 컨슈머 그룹(example-group)을 설정하여, 토픽에서 메시지를 읽을 때 호출됩니다. 컨슈머 그룹은 다수의 컨슈머가 병렬로 데이터를 처리할 수 있도록 하는 단위입니다. 같은 그룹의 컨슈머는 토픽의 파티션을 나눠서 처리하며, 각 파티션은 한 번에 하나의 컨슈머만 읽을 수 있습니다.
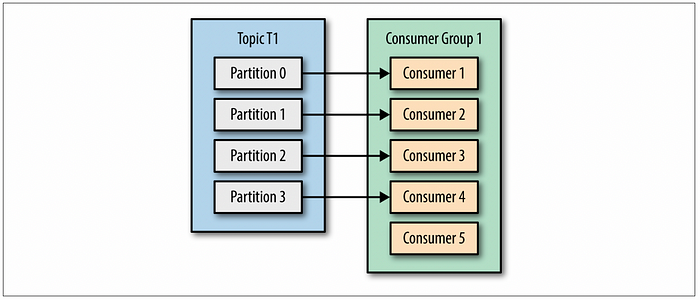
컨슈머 그룹 설정에서 주의해야 할 점은 병렬 처리와 메시지 처리량이에요. 같은 그룹 ID를 사용하는 컨슈머가 많아질수록 파티션의 개수와 균형이 중요해요. 예를 들어, 4개의 파티션이 있는 토픽에 5개의 컨슈머를 같은 그룹으로 설정하면, 1개의 컨슈머는 대시 상태가 되어 비효율적입니다. 따라서 파티션 수와 잘 맞추거나 컨슈머를 적절히 조정해야 합니다.
spring:
kafka:
listener:
concurrency: 4
이 설정은 최대 4개의 스레드로 메시지를 병렬 처리하도록 만듭니다. 하지만 파티션 수가 1이라면 아무런 효과가 없으므로, 병렬 처리가 필요한 경우 파티션 수를 늘리는 것도 고려해야 해요.


