아파치 카프카는 마이크로서비스와 같은 현대적인 아키텍처에서 매우 유용하게 활용되는 오픈소스 메시지 스트리밍 플랫폼입니다. 현재 여러 IT 서비스와 플랫폼에서 표준처럼 사용되고 있지만, 실제로 카프카를 활용한 서비스 개발 과정에서는 주의해야 할 점이 적지 않습니다. 🤔
이러한 문제의식을 바탕으로, 아파치 카프카의 기본 개념을 정리하고 실무 관점에서의 장점과 개발 시 유의점을 다뤄보려 합니다.
일단 가볍게 아파치 카프카에 대해서 적으려고 합니다.
아파치 카프카는 2011년 링크드인(LinkedIn)에서 처음 개발된 후, 현재는 아파치 소프트웨어 재단(Apache Software Foundation)에서 관리하는 오픈소스 프로젝트입니다. 당시 링크드인은 수많은 데이터를 실시간으로 처리하며 여러 문제가 발생했는데, 다수의 데이터 프로듀서(Producer)와 컨슈머(Consumer)가 개별 연결을 맺는 구조로 인해 통신 복잡도가 기하급수적으로 증가했습니다.

이를 해결하기 위해 중앙에서 메시지와 데이터 흐름을 관리하는 구조를 설계했고, 이 과정에서 만들어진 것이 바로 카프카입니다.
카프카는 전통적인 메시지 큐 시스템(RabbitMQ, ActiveMQ 등)과 비교했을 때, 처리량, 처리 속도, 가용성, 확장성 면에서 매우 우수합니다. 이 때문에 링크드인을 비롯한 많은 IT 기업들이 카프카를 채택하여 운영하고 있습니다.
특정한 개념을 설명할 때에는 이를 하나의 명확한 문장으로 표현하는 것도 방법이지만, 해당 개념을 구성하는 여러 요소를 하나씩 뜯어보면서 전체 개념을 파악할 수 있게 하는 것도 방법이 될 수가 있죠.🤓
해당 글에서는 카프카를 구성하는 여러 요소를 하나씩 설명하면서 카프카 전체의 개념을 파악할 수 있도록 합니다.
각각의 요소를 자세히 설명하면서 카프카 전체의 개념을 전달하고자 합니다.
브로커(Broker)
하나의 카프카 서버를 브로커(Broker)라고 합니다. 브로커는 프로듀서로부터 메시지를 수신하고 오프셋을 지정한 후 해당 메시지를 디스크에 저장합니다. 또한 컨슈머의 파티션 읽기 요청에 응답하고 디스크에 수록된 메시지를 전송합니다.
카프카의 브로커는 클러스터(Cluster)의 일부 구성원으로 동작하도록 설계되었습니다. 여러 개의 브로커가 하나의 클러스터에 포함될 수 있으며, 그중 하나는 클러스터의 컨트롤러 역할을 수행합니다. 컨트롤러는 클러스터 내의 각 브로커에게 담당 파티션을 할당하고, 브로커들이 정상적으로 동작하는지 모니터링합니다.
클러스터(Cluster)
여러 대의 분산 서버를 네트워크로 연결하여 마치 하나의 거대한 서버처럼 동작하게 만드는 개념을 서버 클러스터링(Server Clustering)이라고 합니다. 여러 대의 서버를 클러스터로 묶게 되면, 특정 서버에서 장애가 발생하더라도 다른 서버에서 외부의 요청을 처리할 수 있기 때문에 서비스 전체의 가용성에는 문제가 발생하지 않는 장점이 있어요.
카프카도 여러 대의 서버(broker)를 묶어서 하나의 거대한 서비스(Cluster)처럼 움직이기 때문에, 특정 서버에 장애가 발생하더라도 카프카를 이용하는 클라이언트에게는 정상적인 처리와 응답을 제공할 수 있습니다. 또한 클러스터 내의 카프카 서버를 추가할 때마다 그만큼 메시지의 수신과 전달에 대한 처리량이 증가하기 때문에 확장성 측면에서도 장점이 있죠.
카프카 클러스터를 확장하는 작업은 시스템 사용에 영향을 주지 않으면서 온라인 상태에서 진행할 수 있습니다.
이러한 유연성 덕분에 초기에는 소규모로 운영을 시작하고, 이후 처리 트래픽의 증가에 맞춰 카프카 서버를 손쉽게 대규모로 확장할 수 있는 이점을 제공합니다. 이는 특히 빠르게 성장하는 서비스 환경에서 큰 강점으로 작용합니다.
토픽과 파티션(Topic, Partition)
카프카의 메시지는 토픽으로 분류합니다. 토픽은 데이터베이스의 테이블이나 파일 시스템의 폴더와 유사해요. 하나의 토픽은 여러 개의 파티션으로 구성될 수 있습니다.
메시지는 파티션에 추가되는 형태로만 기록되며, 맨 앞부터 제일 끝까지의 순서로 읽습니다. 대개 하나의 토픽은 여러 개의 파티션을 갖질 수 있지만, 메시지의 처리 순서는 토픽이 아닌 파티션별로 관리됩니다.
이때 각 파티션은 서로 다른 서버에 분산될 수 있는데, 이러한 특징 때문에 하나의 토픽이 여러 서버에 걸쳐 수평적으로 확장될 수 있어요. 이는 단일 서버로 처리할 때보다 훨씬 높은 성능을 가질 수 있게 해 줍니다.
메시지(Message)
카프카에서는 데이터의 기본 단위를 메시지(Message)라고 부르며, 이는 모든 데이터 형태를 바이트 배열로 저장할 수 있는 구조입니다. 덕분에 특정 형식이나 의미에 구애받지 않고 데이터를 저장할 수 있죠. 이후 메시지를 읽어올 때는 원하는 형태로 변환하여 사용할 수 있어 다양한 활용이 가능합니다.
카프카의 메시지는 토픽 내의 파티션에 기록되는데, 이때 특정 메시지를 기록할 파티션을 결정하기 위해 메시지에 담긴 키 값을 해시 처리하고, 그 값과 일치하는 파티션에 메시지를 기록하게 됩니다. 여기서 메시지의 키 값을 해시 처리하는 로직을 파티셔너(Partitioner, 메시지를 기록하는 파티션을 선택하는 컴포넌트)라고 합니다.
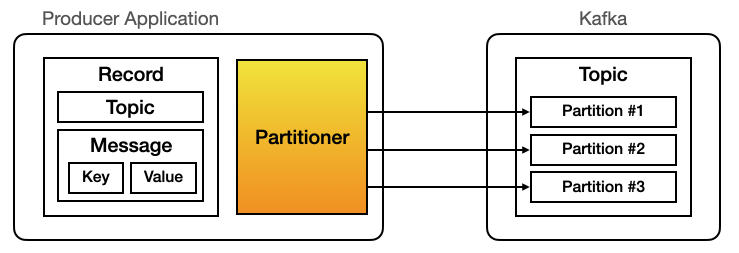
이러한 원리 때문에 동일한 키 값을 가지는 여러 개의 메시지는 항상 동일한 파티션에 기록되게 됩니다. 만약 키 값의 null로 전달된다면 카프카 내부의 기본 파티셔너는 각 파티션에 저장되는 메시지 개수 균형을 맞추기 위해 라운드 로빈(Round-Robin) 방식으로 메시지를 기록해요.
프로듀서와 컨슈머(Producer, Consumer)
카프카의 클라이언트는 프로듀서(Producer)와 컨슈머(Consumer)가 있습니다.
프로듀서(Producer)는 새로운 메시지를 특정 토픽에 생성하는데, 이때 프로듀서는 기본적으로 메시지가 어떤 파티션에 기록하는지는 관여하지 않아요. 만약 프로듀서가 특정한 메시지를 특정한 파티션에 기록하고 싶을 때에는 메시지 키와 파티셔너를 활용할 수 있습니다.
파티셔너는 키의 해시 값을 생성하고 그것을 특정 파티션에 대응시키는데, 이러한 방식으로 지정된 키를 갖는 메시지가 항상 같은 파티션에 기록되게 해 줍니다.
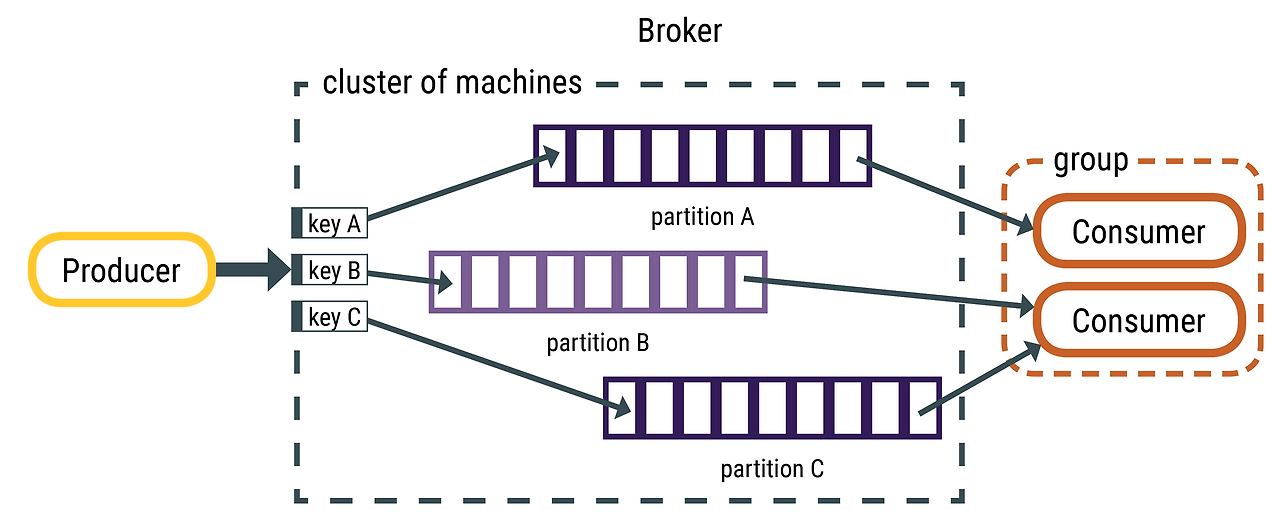
컨슈머(Consumer)는 하나 이상의 토픽을 구독하면서 메시지가 생성된 순서로 읽습니다. 컨슈머는 메시지를 읽을 때마다 파티션 단위로 오프셋을 유지하여 읽는 메시지의 위치를 알 수 있죠. 오프셋의 종류는 Commit Offset과 Current Offset이 있는데 Commit Offset은 컨슈머로부터 "여기까지 오프셋은 처리했다."는 것을 확인하는 오프셋이고, Current Offset은 컨슈머가 어기까지 메시지를 읽었는지를 나타내는 오프셋이에요. 각각의 파티션마다 오프셋이 있기 때문에 컨슈머가 읽기를 중단했다가 다시 시작하더라도 언제든 그다음 메시지부터 읽을 수 있게 됩니다.
컨슈머 그룹(Consumer Group)
카프카 컨슈머들은 컨슈머 그룹(Consumer Group)에 속하게 됩니다. 여러 개의 컨슈머가 같은 컨슈머 그룹에 속할 때에는 각 컨슈머가 해당 토픽의 다른 파티션을 분담해서 메시지를 읽을 수 있습니다. 이처럼 하나의 컨슈머 그룹에 더 많은 컨슈머를 추가하면 카프카 토픽의 데이터 소비를 확장할 수 있어요. 즉, 더 많은 컨슈머를 추가하는 것이 메시지 소비 성능 확장이 중요한 방법이 되죠.
이때 주의할 점은, 한 토픽의 각 파티션은 하나의 컨슈머만 처리할 수 있다는 것이에요. 그렇기 때문에 하나의 토픽 내의 파티션 개수보다 더 많은 수의 컨슈머를 추가하는 것은 의미가 없다는 것을 명심해야 해요. 그리고 각 컨슈머가 특정 파티션에 대응되는 것을 파티션 소유권(Partition Ownership)이라고 합니다.
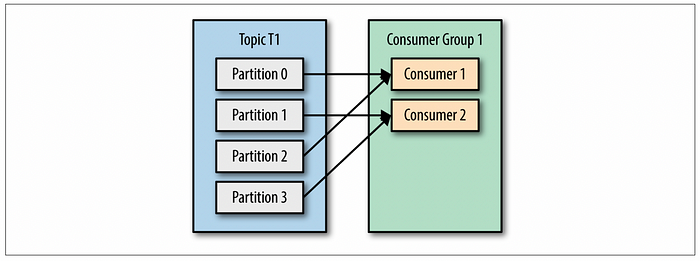
파티션이 컨슈머보다 많다면, 하나의 컨슈머가 여러 개의 파티션을 처리해야 하기 때문에 지연(lag)이 발생할 수 있습니다.
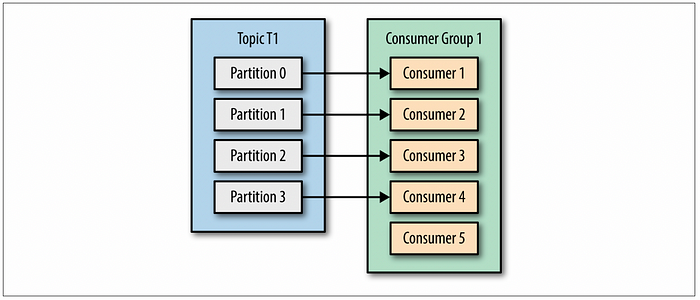
또한 컨슈머의 수가 파티션의 수보다 많다면, 놀고 있는 컨슈머가 생기기 때문에 비용을 낭비하게 됩니다. 참고로 파티션의 수는 늘릴 수는 있지만 줄일 수는 없습니다. 따라서 무작정 파티션과 컨슈머의 수를 많이 늘리기보다는 테스트를 통해서 지연이 발생하지 않는 최적의 파티션 수와 컨슈머 수를 찾아내는 것이 중요합니다.
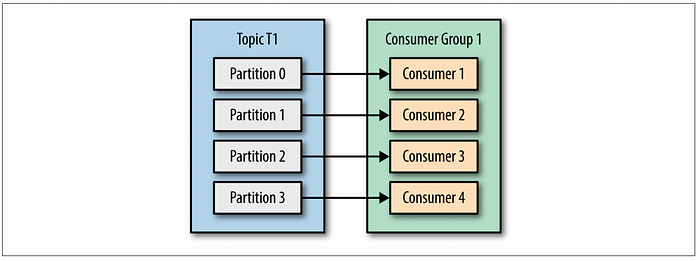
카프카는 하나의 토픽에 여러 개의 컨슈머 그룹이 붙어서 메시지를 읽을 수 있는 다중 컨슈머 기능을 제공하는데, 여러 개의 컨슈머 그룹이 서로 간의 상호 간섭 없이 각자의 오프셋으로 각자의 순서에 맞게 메시지를 읽고 처리할 수 있어요. 같은 토픽의 메시지를 읽어야 하는 여러 개의 애플리케이션이 있다면 각각의 애플리케이션마다 각자의 컨슈머 그룹을 갖도록 하면 되는데, 이 때문에 보통 컨슈머 그룹명을 애플리케이션 이름과 일치시켜 관리하는 편이 좋습니다. 간단히 말해 컨슈머 그룹은 애플리케이션의 단위라고 생각하면 좋아요.
아파치 카프카에 대해 매우 간략하게 알아보기
Quick introduction about Kafka, the most popular message queue structure among developers.
wnjoon.github.io
10분안에 알아보는 Kafka
카프카란 무엇인가?
medium.com
[KafKa] 카프카 클러스터(Cluster)와 브로커(Broker)
브로커? 클러스터? 주키퍼? 브로커 브로커는카프카 클라이언트와 데이터를 주고 받기 위해 사용하는 주체입니다. 1대의 서버에는 하나의 브로커가 올라옵니다. 클러스터 클러스터는 다음사진과
gyuturn.tistory.com
How Apache Kafka messages are written
Overview of the Apache Kafka™ topic data pipeline. Apache Kafka™ is a distributed streaming message queue. Producers publish messages to a topic, the broker stores them in the order received, and consumers (DataStax Connector) subscribe and read messag
docs.datastax.com
Apache Kafka 간략하게 살펴보기
본 문서는 “카프카 핵심 가이드 (제이펍)” 를 참고하였습니다.
medium.com
Kafka Producer and Consumer
I talked about Kafka architecture in my previous article. In this article, I will talk about the issues of producer and consumer with…
medium.com


