오늘은 합병 정렬에 대해서 공부해보았습니다~
합병 정렬(merge sort) 이란?
분할 정복을 사용해서 정렬하는 알고리즘인데, 분할 정복은 하나의 문제를 두 개로 나누어서 두 개의 문제를 각각 해결하여 원래의 문제를 해결하는 것인데, 간단한 예로 들자면 정렬되지 않은 한 개의 배열을 순환적으로 두 개의 배열로 나누어서 배열의 크기가 1이 될 때 각각 나누었던 배열을 다시 합치면서 정렬시키는 것이에요~
합병 정렬(merge sort) 알고리즘에서는 분할(Divide), 정복(Conquer), 결합(Combine) 단계들로 이루어지는데, 분할(Divide)은 배열을 같은 크기의 2개의 부분 배열로 분할하고, 정복(Conquer)은 나누어진 배열을 정렬을 시킵니다.
마지막으로 정복(Conquer)은 정렬된 부분 배열을 다시 하나의 배열로 합병을 함으로써 끝이 나는 알고리즘이에요
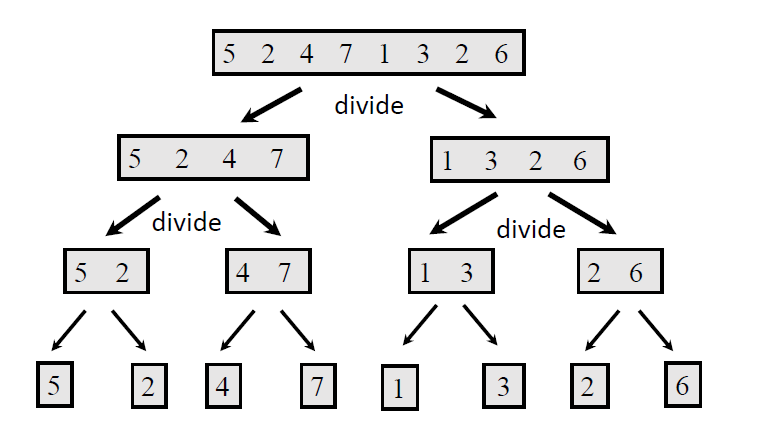
합병 정렬(merge sort) 예시 - 그림

합병정렬(merge sort) c언어 코드 & 수도 코드



merge_sort 함수는 맨 왼쪽 인덱스와 오른쪽 끝 인덱스를 입력받아 왼쪽 인덱스와 오른쪽 인덱스를 더해서 2로 나눈 가운데 인덱스를 구해서 다시 merge_sort에 가운데 인덱스를 기준으로 merge_sort에 다시 넣어서 왼쪽 부분 배열과 오른쪽 부분 배열에 넣어서 순환 호출을 해서 배열 크기가 1일 때까지 반복해요~ 배열 크기가 1이 되면 다음 함수인 merge함수로~~

원래 전역 변수로 정렬된 배열을 지정하는데 저는 일부로 temp라는 임시 배열을 계속 불러왔어요
merge 함수는 간단합니다! 첫 번째 while문은 분할 정렬된 배열을 합병하는 작업을 하는데 temp배열에 조건문에 맞춰서 arr배열을 임시 저장하고, 밑에 조건문 if-else는 남아있는 값들을 왼쪽 오른쪽 전부 복사를 합니다! 마지막 for문은 임시 저장된 정렬된 temp 배열을 마지막 arr배열에 재복사함으로써 정렬이 끝납니다!
합병 정렬(merge sort) 시간 복잡도

합병 정렬의 시간 복잡도는 어떻게 될까요?? 합병 정렬은 3가지의 단계로 나눠진다고 앞에서 말했죠?? 분할(Divide) 과정에서는 비교 연산과 이동 연산이 수행되지 않기 때문에 Θ(1)가 걸리고, 정복(Conquer) 과정에서는 순환 호출 과정으로 merge_sort 함수에서 본 것처럼 하나의 배열을 가운데로 기준으로 왼쪽과 오른쪽으로 나눠서 반복적으로 순환 호출을 하였죠?? 그래서 시간은 2T(n/2) 이 걸려요. 마지막으로 결합(Combine) 과정에서 n번의 비교 연산과 레코드의 이동이 2n번 일어나기 때문에 Θ(n)이 걸립니다.
결과적으로 합병 정렬에서 시간은 정복 과정과 결합과정에서 시간이 걸립니다. 즉 정복 과정에서 순환 호출의 깊이만큼의 합병 단계 * 각 합병 단계의 비교 연산이 합병 정렬의 시간 복잡도겠죠??
시간 복잡도 : 2n(비교 연산, 이동 연산-결합(Combine)) * log 2n (순환 호출 - 정복(Conquer)) = 2nlog 2n = Θ(nlog(n))
합병 정렬은 배열로 구성하게 되면 임시 배열이 필요하며 , 크기가 클 경우 이동 횟수가 많아지므로 매우 큰 시간이 낭비됩니다. 하지만 입력 데이터가 무엇이든 간에 정렬되는 시간은 동일하는 엄청난 장점이 있으므로 효율적인 알고리즘이라 생각합니다.
'Computer Science > Data Structure' 카테고리의 다른 글
| [자료구조] 큐(queue) 란? - 컴도리돌이 (0) | 2020.01.05 |
|---|---|
| [자료구조] 스택(stack)의 응용2 : 후위 표기(postfix) 계산 - 컴도리돌이 (0) | 2020.01.05 |
| [자료구조] 스택(stack)의 응용1 : 괄호검사 - 컴도리돌이 (0) | 2020.01.05 |
| [자료구조] 스택(Stack) 이란? - 컴도리돌이 (0) | 2020.01.05 |
| [알고리즘] 삽입 정렬 (Insertion Sort) 이란? - 컴도리돌이 (3) | 2019.12.29 |



